Présentation
On peut distinguer deux niveaux de représentation de la langue, le premier s'occupant de compétence et le second de performance. Il sera donc question dans cette partie de tenter de dégager les traits relatifs à la performance.
Shapiro (1992) rappelle que la linguistique s'occupe principalement de modèles généraux et structuraux de la langue naturelle. Ainsi les linguistes tendent à prévilégier des modèles formels permettant la représentation des régularités du langage propres à la généralisation. Les modèles ainsi produits caratérisent le langage lui-même et ne se préoccupent pas ou peu des mécanismes conduisant à leur production ou à leur décodage. Ainsi la grammaire générative transformationnelle de Chomsky constitue un bon exemple d'un modèle peu computable de compréhension du langage.
Shapiro décrit ainsi le traitement du langage naturel (Natural Language Processing) comme étant la formulation et la recherche des mécanismes efficaces à l'śuvre dans la communication du langage naturel. Il décrit le domaine de recherche du NLP comme n'étant pas l'étude abstraite de la communication dans le langage naturel mais comme étant préoccupé de réaliser une telle communication dans un modèle computable. Le domaine de recherche du NLP, se distingue donc de la linguistique et des sciences cognitives desquelles elle hérite toutefois des diverses recherches théoriques en tentant d'en faire des modèles opérationnels.
L'une des difficultés propre au traitement de la langue est le traitement des ambiguïtés. Il est naturel dans la langue courante de ne pas formuler explicitement tous les éléments d'une phrase utilisant le contexte ou les connaissances du monde. Lorsque le traitement de telles phrases est confié à des machines, les connaissances inférées doivent être accessibles pour permettre une compréhension adéquate de la phrase.
Deux aspects sont habituellement retenus ici selon que l'on cherche à comprendre le langage naturel ou à le générer. La compréhension du langage naturel implique la représentation des connaissances et ses rapports avec les connaissances du monde alors que la génération du langage refère davantage aux règles de réécriture.
Une des façons d'illustrer la représentation de la phrase est d'utiliser les arbres syntaxiques. Un arbre syntaxique est produit en remplaçant chacune des occurrences de la phrase par son symbole représentant les règles de réécriture de la grammaire non-contextuelle ou grammaire générative La figure 5 présente les symboles et abréviations utilisées pour en identifier les divers constituantsLa représentation de la phrase
| nom complet | abréviation |
|---|---|
|
Phrase Syntagme nominal Déterminant Adjectif Nom Syntagme verbal Verbe Préposition Syntagme prépositionnel |
P SN DET ADJ NOM SV V PREP SP |
Fig. 5 Constituants et abréviations utilisés par les arbres syntaxiques.
A l'aide de ces outils, il est possible de créer des règles assurant une représentation de la phrase: Ainsi, l'analyse de la phrase "Le chien de la voisine aboie la nuit" produira la suite de règles suivantes répondant à sa représentation:
Ple chien de la voisine aboie la nuit |
Lequel peut par la suite être représenté dans un arbre syntaxique de la façon suivante:
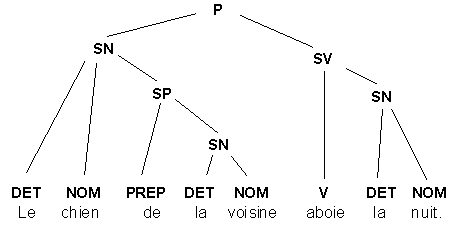
Fig. 6 Arbre syntaxique
La réalisation d'une telle analyse se fait en suivant à l'envers les règles de réécriture de la phrase. Plutôt que de partir du sommet de l'arbre, on part plutôt de la phrase elle-même en remplaçant les symboles désignés par la partie gauche de la règle. L'arbre sera ainsi construit à l'envers. Voici la procédure appliquée à notre première phrase:
Le chien de la voisine aboie la nuit. |
Bien que les arbres syntaxiques permettent de dresser efficacement une certaine représentation de la phrase, ils ont aussi leurs limites parmi lesquelles il faut mentionner leur peu de facilité à traiter du temps des verbes ainsi que des marques du pluriel, et leur totale incapacité à reconnaître la non-grammaticalité de certaines phrases.
Parmi les solutions apportées à ces problèmes mentionnons les réseaux de transitions. On appelle réseau de transition un réseau composé de noeuds et d'arcs étiquettés. Ces réseaux permettent de définir les mécanismes de constructions des noeuds en jeu dans les arbres syntaxiques utiles aux analyseurs syntaxiques. Les réseaux tentent d'expliquer le chemin à pratiquer dans l'arbre syntaxique pour répondre à la représentation de la phrase. Les réseaux de transition récursifs emploient l'analyse descendante. La figure 7 dresse un réseau de transition récursif de la phrase "Le chien de la voisine aboie la nuit"
Fig. 7 Réseau de transitions
Les grammaires hors contexte tout comme les grammaires à réseaux de transitions récursifs ne permettent pas d'afficher toutes les contraintes syntaxiques. On augmentera le pouvoir des réseaux en leur adjoignant la possibilité de conserver des traces des déplacements effectués. Ces réseaux seront appelés réseaux enrichis ou ATN (Augmented Transition Networks) (Woods 1970). Ils permettront de rattacher des traits sélectifs capables de caractériser par exemple le nombre. Ces ATN utilisent un tampon de mémoire permettant de stocker temporairement les résultats du parcours d'un arc.
Les Frames (traduits par cadres ou structures), dans leur définition la plus large, représentent un ensemble de faits et d'objets, auxquels s'ajoutent des stratégies d'inférences permettant le raisonnement, décrivant une situation ou un objet typique. Minsky (1964) fut le premier à produire cette conception d'une base de connaissances qui fut par la suite reprise et adaptée par d'autres: Fillmore (1968), Simmons (1973), Schank (1975), Riesbeck (1975). Les dernières incarnations des frames se nomment Case Frames et sont particulièrement utiles pour leur récursivité, leur habilité à combiner des reconnaissances de concepts clés ascendantes avec des instanciations descendantes d'éléments moins structurés.
La phrase: "Stéphane a ouvert un pot pour Julie dans la cuisine." pourrait s'exprimer de la façon suivante:
[OUVRIR
[case frame
agent: STÉPHANE
objet: POT
location: CUISINE
beneficiaire: JULIE]
[mode
temps:passé
voix: actif]]
|
L'ensemble des connaissances amassées ici constituent, avec les autres frames, une base de connaissances (Knowledge Base) où les diverses structures d'informations sont définies sémantiquement et non plus syntaxiquement ce qui leur accorde une certaine liberté et la possibilité de traiter de techniques comme le choix des mots ou la paraphrase au moment de la réécriture. Ils peuvent aussi tenir compte du temps des verbes, problème que les solutions précédentes ne pouvaient régler convenablement.
On doit à Sowa (1984) la notion de graphe conceptuel. L'utilisation des graphes conceptuels permet de représenter les relations entre les divers éléments de la phrase. Dans le graphe conceptuel, la boîte contient le concept, le cercle, la relation et des traits orientés entre les divers éléments dirigent le sens de la lecture. La figure représente la phrase "Pierre se rend à Montréal en voiture".
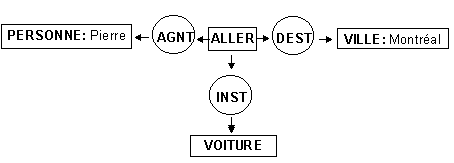
Fig. 8 Graphe conceptuel
Ce graphe conceptuel (G.C.) a l'avantage de représenter des données qui sont indépendantes de la langue parlée. Ainsi il serait possible d'utiliser le même G.C. pour en représenter la version anglaise de la phrase "Peter goes to Montreal by car".
De plus, tels qu'ils sont conçus, les G.C. reposent sur un système de logique et peuvent ainsi être représentés par la logique des prédicats. L'analyse de la figure précédente révèle l'emploi de quatre termes étiquettés soit PERSONNE, VA, VILLE et VOITURE. Ces termes se traduisent en prédicats simples: personne(x), va(x), ville(x), et voiture(x). Les relations conceptuelles créent le lien orienté entre les divers termes: agnt(x,y), dest(x,y), int(x,y). L'expression de ce graphe en logique des prédicats du premier ordre donne donc l'expression suivante:

Par cette formule il est dit qu'il existe un x et un y tel que Pierre est une personne, x est est une instance d'aller, Montréal est une ville, y est une voiture, l'agent de x est Pierre, l'instrument de x est y et la destination de x est Montréal. (adapté de Sowa).
Le même graphe conceptuel peut aussi être représenté par une notation linéaire:
[ PERSON: Pierre] ¬ (AGNT)¬ [ ALLER] ® (DEST)® [ VILLE: Montréal] .
Dans le cas de phrases plus longues, pour éviter que la formule ne prenne plusieurs lignes et ne devienne difficile à lire, il est possible d'adopter une représentation sur plusieurs lignes:
|
[ALLER]-
|
Sowa nous rappelle que sous cette forme le G.C. ressemble à un Frame, les relations conceptuelles s'apparentant aux "slots" les étiquettes de type aux contraintes et les noms Pierre et Montréal aux contenus des "slots". Toutefois, contrairement aux Frames qui ne savent représenter qu'une sous section de la logique, les G.C. permettent de représenter toute la logique étant plus généraux.
Dans le graphe conceptuel, le concept est donc représenté par une boîte ou entre crochets et les relations sont représentées par des cercles avec une flèche entrante et une autre sortante ou entre parenthèses, les flèches symbolisant les liens entre ces concepts. Dans un graphe conceptuel, un concept les objets ont un type, ici Pierre est de type PERSONNE et un référent précisant l'instance du type précédent.
Le référent quant à lui, précise le sens du concept. Il permet de distinguer un concept générique d'un concept précis et joue le même rôle que le déterminant en langue naturelle. C'est ainsi qu'il peut donner le degré de quantification du concept, qu'il soit quantifié explicitement par un nombre ou bien de manière qualitive.
S'il s'agit d'un concept générique le référent n'aura pas à être instancié
[CHIEN : * ] ou [CHIEN] ® "un chien"
alors qu'un concept individuel, faisant référence à un individu du type mentionné, sera personnalisé par un numéro d'ordre ou par son nom :
[CHIEN : 'Fido'] ®"Fido"
Dans l'exemple employé plus haut, PERSONNE : Pierre il faut voir une notation contractée dont la forme étendue serait:
[PERSONNE : #3452] ® (NOM) ® [MOT : "Pierre"]
Les quantités seront exprimées en utilisant l'opérateur SET(...)
[CHIEN : SET(*)] ® "des chiens"
Une relation peut utiliser plusieurs arcs. Ainsi la relation entre (between) dans l'expression "chien entre la niche et la grosse maison" produira le graphe conceptuel suivant:
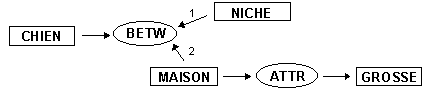
Qui pourra aussi s'écrire, de façon linéaire:
[CHIEN] ¬(BETW) -
1 ¬[NICHE] |
Sowa étend encore la portée du graphe conceptuel en lui permettant d'exprimer des propositions inbriquées. Dans la phrase "Jean croit que Lucie veut rencontrer Pierre qui est écrivain" se trouve en fait trois propositions "Jean croit" et "Lucie veut" et la situation: " rencontrer un écrivain". Voici le graphe produit:
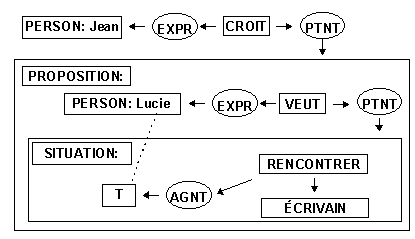
Ici l'ajout d'une boîte autour du graphe conceptuel permet d'exprimer le contexte. Ces imbrications de contextes peuvent devenir rapidement complexes avec l'ajout de niveaux supplémentaires mais elles permettent une représentaiton juste. La ligne pointillée unissant Lucie au T (Type universel) permet l'inférence (T = Lucie).
Avec l'expression du contexte, Sowa peut aussi exprimer un contexte négatif ou la négation d'un graphe conceptuel:

Ø[[ PERSONNE: Jean ]¬[ TRAVAILLER]]
Ici les imbrications s'expriment en répétant le crochet et la négation se place au devant de la boîte concernée.
De par leur lien avec la logique les G.C. permettent donc de multiples opérations sur le langage. Ils permettront de résoudre l'expression de la pluralité par l'utilisation de référents et d'ensembles, ils permettront aussi d'aborder un problème particulièrement important, celui du temps de l'action. A l'aide de diverses variables, ils pourront décrire un événement comme étant composé de diverses situations pouvant comprendre à leur tour divers attributs dont un moment de départ et un moment de complétion desquels pourront découler la notion de durée de l'événement.
Quels sont les domaines d'application du traitement du langage naturel? Ils sont multiples et répondent à des questions et des besoins divers. On est de plus, en droit à s'attendre à une croissance importante des applications allant de pair avec le développement de la compréhension du traitement du L.N. Il est à remarquer que les applications les plus réussies sont encore celles qui collent à un domaine de travail spécifique voire spécialisé. Ainsi certains traducteurs de bulletins météos où les données appartiennent toutes à un domaine spécialisé réduisent considérablement le travail de mise en texte. Voici quelques travaux dignes de mention, tous tirés de la revue de Nogier (1991). L'un des premiers et des plus célèbres systèmes de production automatique est certainement Eliza dans lequel Weizenbaum (1966) prête à son programme des intentions psychanalytiques en le nourissant d'un certain nombre de phrases du domaine et en lui faisant adopter systématiquement le ton interrogatif. ELIZA produit des dialogues semblant naturels. Puis vient SHRDLU Winograd (1972) qui, reprenant les pistes amorcées par le précédent, pousse un peu plus loin en appliquant des procédures de raisonnement permettant de remplir un moule de type phrase à trous. Ce patron est souvent employé de par sa simplicité. Son efficacité est liée au domaine d'application. Balpe (1986) s'est illustré avec de nombreux programmes dont la mission est d'engendrer de petits textes poétiques ou littéraires. (HAIKU, RENGA, ROMAN) . Utilisant les dépendances conceptuelles et la théorie des plans et buts développé par Schank et Abelson (Shank 1977), TALE-SPIN de J.R. Meechan (1977) crée de courts récits à la façon de nouvelles. L'indice boursier est produit à partir du Dow Jones, en anglais avec ANA (Kukich 1983) puis en français FRANA (Constant 1985). Il s'agit ici d'un bon exemple d'un domaine spécialisé influençant le schéma de texte, le type de discours produit et limitant la production littéraire à des phrases choisies. TEXT de McKoown (1985) permet des réponses d'une dizaine de lignes à des questions sur la structure d'une base de données militaires. Utilise un schéma de questions-réponses commandant un moule de réponses associées. Ce programme est aussi le premier à utiliser une grammaire fonctionnelle d'unification (FUG) pour construire sa structure de surface. SCHOLAR réalisé par Carbonnell (1973) et Collins permet de répondre à des questions de type scolaires dans le domaine de la géographie. Simonin (1985) travaillant dans un domaine similaire utilise des règles de filtrage pour juger des informations pertinentes à transmettre. RAREAS (Kittredge 1986) développe un systéme de gestion de bulletins de météos où le choix des termes à employer est commandé par des paramètres liés à l'intensité des phénomènes observés. Danlos (1985-87) travaille sur les aspects linguistiques de la génération de langage. Elle utilise un lexique-grammaire et produit le texte en utilisant une grammaire du discours, située entre la phrase et le texte et fournissant les schémas de phrases utilisables pour exprimer la relation conceptuelle donnée. Tenant compte d'une grille de buts d'expression, KDS (Knowledge Delivery System) (Mann 1981) construit un texte structuré à partir de données brutes. Ce programme utilise un modèle de lecteur pour effectuer la sélection du contenu. Mann et Matthiessen (1984) sont aussi connus pour le développement d'un projet ambitieux appelé NIGEL utilisant une grammaire systémique de génération avec le concours de nombreux linguistes. PAULINE (Planning And Uttering Language In Natural Environnements) tente de tenir compte des attentes du lecteur pour produire, à partir d'une même représentation sémantique d'entrée, divers textes. Réalisé par Hovy (1984) ce système utilise différents tons pour intéresser le lecteur, à la manière du journaliste. Le procédé est commandé par des schémas rhétoriques (Generational Scripts) semblables aux schémas de réponses de McKeown (1982). Capable ce choisir ses mots et produire des paraphrases, BABEL de Goldman (1975) est un module de production de phrases utilisant les réseaux de transition augmentés (ATN) de Woods (1970) Jacobs (1983) produit un module de génération PHRED, qui utilise la même base de connaissances lexicales pour l'analyse et la génération. Le type de représentation utilisé se base sur le Pattern Concept, permettant de conserver diverses significations d'un mot et de les utiliser selon le contexte. Il améliorera le Pattern Concept et lui adjoindra des processus d'héritage dans Ace (1986). Boyer et Lapalme (Boyer 1985), utilisent le modèle de représentation des connaissances de Mel'cuk: les réseaux sémantiques Sens Û
Texte où la construction de la phrase se fait en plusieurs étapes supposant un certain nombre de lectures tenant compte de la théorie. Dans XPLAIN, Swartout (1981), l'utilisateur peut demander des explications sur des décisions à divers stades du processus d'expertise. Dans l'enseignement des langues, les travaux de Zock (1986, 88), de Carrol (1980) et de Bates (1981) sont retenus. Dans une étude sur la génération automatique du langage naturel, Nogier (1991) présente une approche traitant le problème de la traduction d'une représentation sémantique en langue naturelle. Ce système, est composé de deux modules, l'un sélectionne simultanément les mots et les structures syntaxiques alors qu'un composant syntaxique effectue les opérations morpho-syntaxiques chargées de produire une phrase bien formée. Le système, KALIPSOS , peut aussi produire des paraphrases ou variations dans le choix des mots employés pour exprimer la même sémantique. Utilisant une modélisation de la signification des mots, il peut revenir sur les choix précédents après avoir construit une première phrase, pour construire une nouvelle phrase de même signification mais faite de mots différents. Ce travail est particulièrement intéressant pour une application du traitement de la langue associé à l'utilisation des graphes conceptuels. Car si la compréhension d'un graphe conceptuel est relativement aisé à effectuer, l'opération inverse, qui consiste à transformer une phrase en graphe conceptuel est loin d'être triviale... demandant le respect intégral de sa signification (p. 51) Nogier (1991) rapporte que: "... la nécessité de formaliser des informations de nature syntaxique amène à étendre le modèle des graphes conceptuels à la syntaxe. ... il est utile de pouvoir employer le même formalisme tout au long du processus des concepts à la phrase. ... un graphe syntaxique représente la syntaxe d'une seule et unique phrase, utilisant comme concepts, les lexèmes des mots de la phrase et comme relations, les relations syntaxiques définissant les rôles syntaxiques des mots dans la phrase" p. 55 Domaines d'application
 |
|
|